
Por Denise Casatti
Publicado na ICMC USP
Quantas vezes você já recebeu uma informação via um aplicativo de troca de mensagens instantâneas, como o WhatsApp, ou leu uma notícia circulando pela Internet e gostaria de checar a veracidade do conteúdo? Agora, já é possível fazer essa verificação usando uma ferramenta piloto criada por um grupo de pesquisadores da USP e da Universidade Federal de São Carlos (UFSCar). A plataforma está em fase de testes e aperfeiçoamento, mas já é possível acessá-la gratuitamente via web ou pelo WhatsApp.
“A gente sabe que, quando uma pessoa está mentindo, inconscientemente, isso afeta a produção do texto. Mudam as palavras que ela usa e as estruturas do texto. Além disso, a pessoa costuma ser mais assertiva e emotiva. Então, uma das formas de detectar textos enganosos é medir essas características”, explica o professor Thiago Pardo, do Instituto de Ciências Matemáticas e de Computação (ICMC) da USP, em São Carlos. Pesquisador do Núcleo Interinstitucional de Linguística Computacional (NILC), Thiago é o coordenador do projeto que resultou na criação da plataforma e na publicação do artigo Contributions to the Study of Fake News in Portuguese: New Corpus and Automatic Detection Results, apresentado no final de setembro na 13ª Conferência Internacional de Processamento Computacional do Português.
“A ideia é que a ferramenta seja um apoio para o usuário. Ainda estamos no início desse projeto e, no estado atual, o sistema identifica, com 90% de precisão, notícias que são totalmente verdadeiras ou totalmente falsas”, pondera o professor. “No entanto, as pessoas que propagam fake news costumam embasar suas mentiras em fatos verdadeiros. Nossa plataforma ainda não tem a capacidade de separar as informações com esse nível de refinamento, mas estamos trabalhando para isso”, completa Thiago.
Para ver como a ferramenta funciona no WhatsApp, por exemplo, pegue seu smartphone e acesse este link: https://otwoo.app/nilc-fakenews. Automaticamente, uma janela de troca de mensagens do aplicativo se abrirá e você vai ler “Nilc-FakeNews” na tela. Basta apertar a tecla enviar e, imediatamente, você receberá outra mensagem: “Olá! Seja bem-vindo ao detector de fake news do NILC-USP – Detecção Automática de Notícias Falsas para o Português! O sistema irá utilizar o modelo de detecção para avaliar se a notícia é falsa ou verdadeira. Insira o corpo de uma notícia.” Pronto, você acabou de acessar o sistema de verificação! Agora, é só colar a notícia que deseja checar. Se forem verificados indícios de fake news, o sistema alertará: “Essa notícia pode ser falsa. Por favor, procure outras fontes confiáveis antes de divulgá-la”.
Após cerca de 20 minutos sem uso, é necessário reativar o acesso ao sistema. Para isso, basta digitar a palavra “Fake” e apertar enviar. Você receberá novamente a mensagem “Olá! Seja bem-vindo…”. Em seguida, pode colar outra notícia e enviar para checagem.

Ensinando o computador – Mas como os pesquisadores conseguiram ensinar o computador a identificar o que é mentira e o que é verdade, se essa tarefa é difícil até mesmo para nós, seres humanos inteligentes? É aí que entram as técnicas da área de inteligência artificial. Para tornar a máquina capaz de reconhecer as características dos textos mentirosos e a dos textos verdadeiros, bem como diferenciá-los, uma série de passos precisa ser realizada.
O primeiro desafio é construir um conjunto de notícias falsas e verdadeiras em português. É a partir do reconhecimento das características desse conjunto de dados que o computador poderá ser treinado para avaliar futuros textos. São as informações que os humanos inserem nas máquinas e os padrões criados para analisar cada conjunto de dados que modelam os sistemas computacionais para que realizem futuras tarefas. Essa é a mesma tecnologia que possibilita ao Facebook, por exemplo, reconhecer faces. Mas por que, então, quando o Facebook começou a fazer reconhecimento facial o índice de acerto era maior quando aparecia o rosto de alguém branco e ocidental? Ora, por causa do viés que havia no conjunto de faces utilizado para treinar a plataforma: a maioria eram imagens de rostos de seres humanos brancos e ocidentais. A questão gerou uma série de críticas à empresa e demandou um aprimoramento da ferramenta.
No caso da plataforma criada para detectar fake news, o conjunto de notícias utilizado é composto por 3,6 mil textos falsos e 3,6 mil verdadeiros, que foram publicados na web entre janeiro de 2016 e janeiro de 2018. Esses textos foram coletados manualmente e analisados para garantir que apenas os que fossem totalmente falsos ou totalmente verdadeiros compusessem o conjunto, que está disponível para utilização em outras pesquisas (veja neste link: icmc.usp.br/e/f9049).
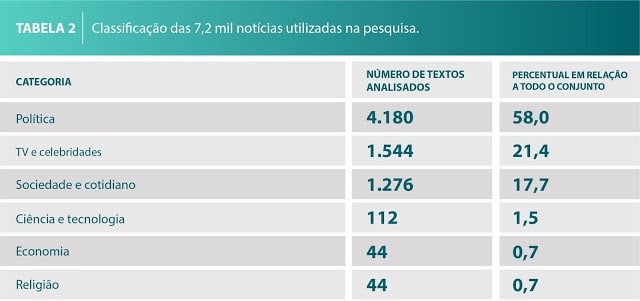
Os conhecimentos da área de inteligência artificial entram em campo na sequência: os cientistas usam técnicas computacionais para processar os textos coletados automaticamente, fazer a classificação gramatical de todas as palavras, separar cada sentença e cada termo (incluindo pontuações e números). Depois, é hora de identificar as características presentes nesses textos que poderiam ser empregadas para classificá-los em falsos ou verdadeiros. Como os textos verdadeiros costumam ser mais extensos que os falsos, a quantidade de palavras e sentenças não é um fator adequado para diferenciá-los. “Se usássemos esse critério, o sistema teria a tendência de classificar todos os textos curtos como falsos e os extensos como verdadeiros”, explica o doutorando Roney Lira, do ICMC. Para evitar isso, os pesquisadores utilizaram outros parâmetros como o número médio de verbos, substantivos, adjetivos, advérbios e pronomes presentes nos textos (veja a tabela a seguir).
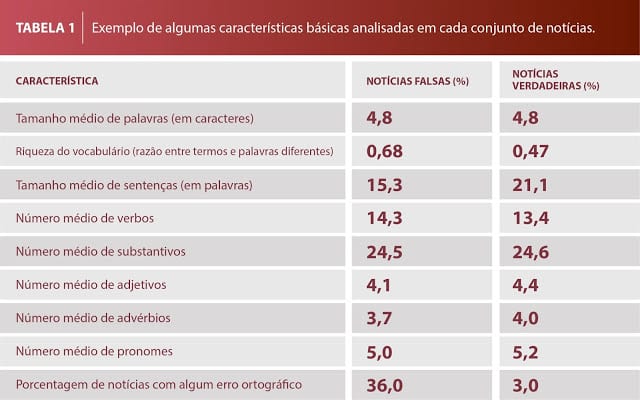
“Das 3,6 mil notícias falsas que coletamos, 36% possuíam algum erro ortográfico, enquanto apenas 3% das verdadeiras apresentavam esse problema”, pondera Roney. Por isso, a presença de um erro ortográfico passou a se tornar um parâmetro relevante para a verificação da veracidade dos textos. Afinal de contas, a probabilidade de uma notícia ser falsa é muito maior se houver um erro ortográfico.
Na penúltima etapa, os pesquisadores lançam mão de outra técnica de inteligência artificial: “Empregamos métodos clássicos de aprendizagem de máquina, que estão entre os mais utilizados atualmente, e conseguimos treinar o sistema com um índice de 90% de acerto na classificação das notícias”, diz Thiago. O professor explica que o índice de acerto é alto porque o sistema avalia, simultaneamente, diversas propriedades presentes nos textos.

Aprendendo e avançando – Cursando Ciências de Computação no ICMC, o estudante Rafael Augusto Monteiro é um dos colaboradores do projeto, do qual participou por meio de uma iniciação científica. Ele já sonha com os desafios futuros: “Nosso intuito inicial foi trabalhar com textos escritos, pois são uma unidade fundamental para análise em linguística computacional. Mas queremos expandir o projeto e passar a avaliar imagens, vídeos, áudios, abarcando outras mídias”.
Já Roney pretende, durante o doutorado, eliminar uma das principais limitações do detector de notícias: avaliar textos que contém partes falsas e verdadeiras, separando o joio do trigo. “O próximo passo é tentarmos fazer checagem de conteúdo automaticamente, algo que as agências de notícias e os jornalistas fazem hoje manualmente”, conta Thiago. O professor também quer avançar na detecção de outros tipos de conteúdos enganosos (do inglês, deception) como as revisões falsas de produtos e os textos satíricos. “A mesma tecnologia da detecção de fake news pode ser usada nesses outros casos mediante adaptações. Nas notícias falsas, o grau de emoção do texto faz diferença. Em textos satíricos, como há sempre exagero, humor, espera-se encontrar alto teor emocional. Então, talvez essa característica deixe de se tornar relevante. Por outro lado, na revisão de produtos, é necessário checar as informações técnicas, por exemplo”.
Financiado pelo Programa Institucional de Bolsas de Iniciação Científica (PIBIC) do CNPq e por outras duas agências de fomento brasileiras (CAPES e FAPESP), o projeto Detecção Automática de Notícias Falsas para o Português conta com a participação de mais três pesquisadores: Evandro Ruiz, que é ex-aluno do ICMC e professor da Faculdade de Filosofia, Ciências e Letras de Ribeirão Preto da USP; Tiago de Almeida, professor do departamento de Computação da UFSCar no campus Sorocaba; e de Oto Araújo Vale, professor do departamento de Letras da UFSCar no campus São Carlos. A equipe teve, ainda, o apoio do doutorando Murilo Gazzola, do ICMC, que foi responsável por disponibilizar a plataforma no WhatsApp. Todo esse trabalho tem sido realizado no âmbito de um projeto maior chamado Opinando (Opinion Mining for Portuguese: Concept-based Approaches and Beyond), que visa fornecer subsídios para a área de mineração de opinião para a língua portuguesa.
Com aproximadamente um ano e meio de vida, o projeto já produziu resultados relevantes e os avanços que poderão ser alcançados no futuro são ainda mais promissores. Mas o professor Thiago ressalta que, por mais que a tecnologia nos ajude na difícil tarefa de identificar as fake news, continuará sendo fundamental a obtenção de informações por meio de fontes confiáveis: “Nenhum sistema será 100% eficiente. Cada vez que se cria algo para detectar um problema, alguém vai descobrir um jeito de burlar”.
Se você acredita que os computadores podem nos salvar das fake news, informamos que essa notícia possivelmente é verdadeira. Mas não exagere: se você escrever que os computadores serão os salvadores da pátria no WhatsApp e enviar para o detector, vai descobrir que essa notícia pode ser falsa. Até o computador reconhece que os sistemas computacionais, tal como os seres humanos, são sujeitos a falhas e que não basta a tecnologia ou um salvador da pátria para solucionar os complexos problemas da humanidade.

Texto e fotos: Denise Casatti – Assessoria de Comunicação do ICMC/USP
Arte das tabelas: Fernando Mazzola
Mais informações:
Site do detector de notícias falsas: http://nilc-fakenews.herokuapp.com/
Link para acessar a ferramenta no WhatsApp: https://otwoo.app/nilc-fakenews
Site do projeto Opinando: https://sites.google.com/icmc.usp.br/opinando/
Conjuntos de notícias verdadeiras e falsas (Fake.Br Corpus): http://icmc.usp.br/e/f9049
Artigo Contributions to the Study of Fake News in Portuguese: New Corpus and Automatic Detection Results (versão pré-impressão): http://conteudo.icmc.usp.br/pessoas/taspardo/PROPOR2018-MonteiroEtAl.pdf
Contato:
Assessoria de Comunicação do ICMC: (16) 3373.9666
E-mail: comunica@icmc.usp.br



