Modelos de linguagem de grande porte (LLMs, na sigla em inglês) estão presentes em diversos aplicativos que usamos diariamente, como sugestões automáticas em mensagens, respostas compostas por assistentes como Gemini e ChatGPT, e imagens geradas por ferramentas como DALL-E. Esses sistemas são treinados com dados reais, incluindo textos e imagens extraídos da internet e outras fontes. No entanto, um estudo recente liderado pelo especialista em segurança computacional David Evans, da Universidade da Virgínia, questiona a eficácia de um método comum para avaliar o risco de vazamento de dados de treinamento desses modelos.
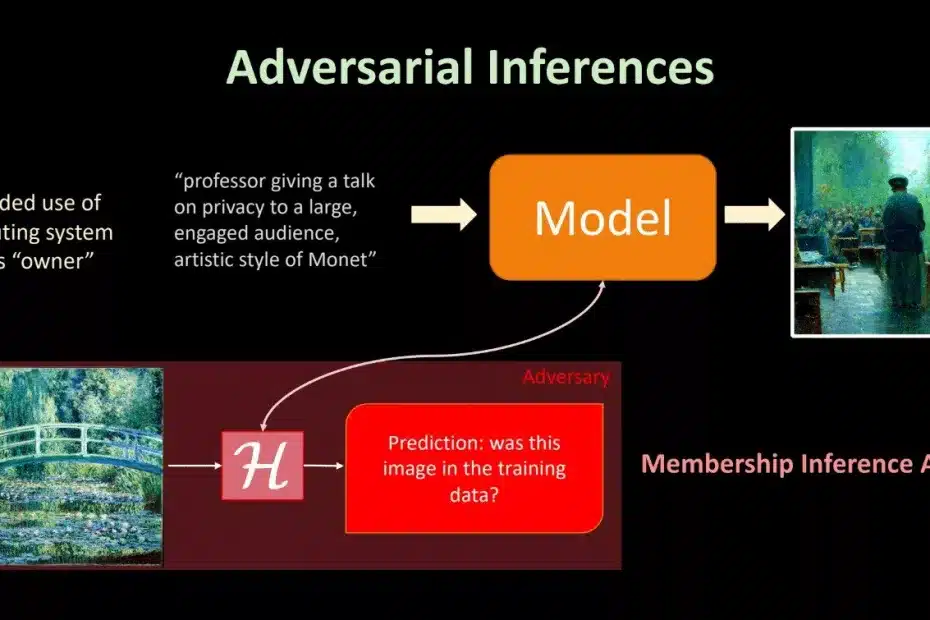
O método em questão envolve ataques de inferência de associação, ou MIAs (Membership Inference Attacks), que avaliam o quanto um modelo expõe informações específicas do conjunto de dados de treinamento. Esses ataques simulam cenários em que adversários tentam determinar se certos dados fizeram parte do treinamento do modelo. Contudo, segundo a pesquisa, apresentada em uma conferência recente sobre modelagem de linguagem, os MIAs muitas vezes não conseguem superar resultados obtidos por simples adivinhações aleatórias, indicando que sua eficácia é limitada.
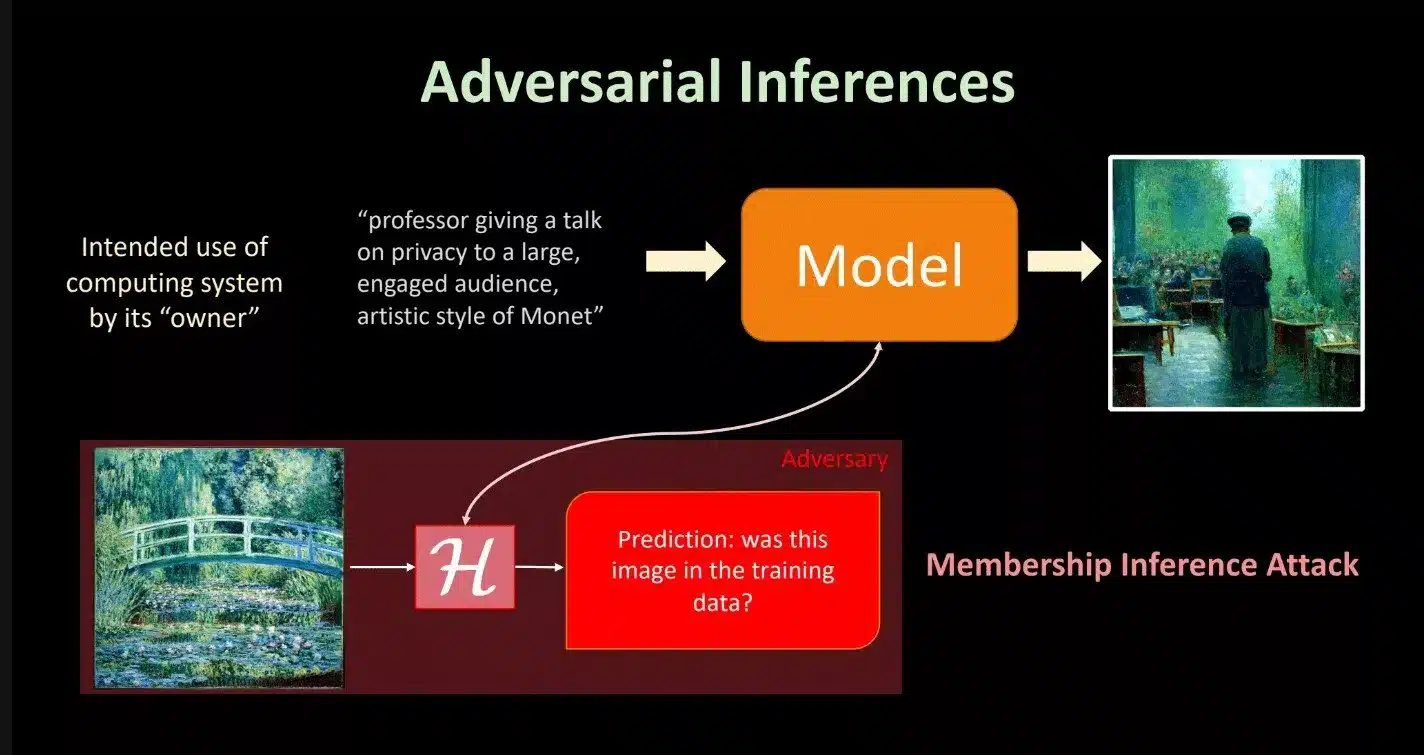
Os LLMs são treinados utilizando grandes volumes de dados textuais coletados de fontes diversas, incluindo sites, repositórios privados e outras bases de dados. Isso torna crucial avaliar a segurança desses dados, uma vez que podem incluir informações sensíveis postadas por milhões de usuários. No entanto, o estudo identificou que os métodos atuais de MIAs enfrentam dificuldades em definir o que é, de fato, um “membro” do conjunto de treinamento, especialmente devido à natureza fluida da linguagem. Diferenças sutis de significado ou variações na escolha de palavras podem dificultar essa definição.
Além disso, a pesquisa aponta que muitos dos resultados positivos de MIAs relatados anteriormente são, na verdade, atribuíveis a mudanças na distribuição de dados ao longo do tempo, em vez de uma detecção efetiva de associação. Por exemplo, dados de treinamento e não-treinamento podem parecer semelhantes, mas terem sido coletados em momentos distintos, resultando em diferenças na distribuição temporal. Essa falha metodológica sugere que os MIAs podem estar medindo outra coisa, como inferências de distribuição, em vez de exposição real de dados.
Apesar das limitações identificadas, os pesquisadores afirmam que o risco de inferência para registros individuais nos dados de pré-treinamento é relativamente baixo, devido ao grande volume de dados utilizados e ao fato de cada trecho ser processado poucas vezes. No entanto, eles alertam que modelos interativos e de código aberto podem abrir novas possibilidades para ataques futuros. Além disso, dados usados em ajustes posteriores, conhecidos como fine-tuning, tendem a ser mais vulneráveis do que os dados originais do treinamento.
Como contribuição, a equipe de pesquisa disponibilizou suas descobertas e ferramentas em um projeto de código aberto chamado MIMIR, permitindo que outros pesquisadores realizem testes mais eficazes de inferência de associação. O estudo destaca que, embora os riscos de vazamento em LLMs sejam baixos, ainda é um desafio mensurá-los com precisão, e a comunidade de inteligência artificial está apenas começando a explorar formas de fazê-lo.